Multiple Comparisons¶
This setup code is required to run in an IPython notebook
[1]:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("darkgrid")
plt.rc("figure", figsize=(16, 6))
plt.rc("savefig", dpi=90)
plt.rc("font", family="sans-serif")
plt.rc("font", size=14)
[2]:
# Reproducability
import numpy as np
gen = np.random.default_rng(23456)
# Common seed used throughout
seed = gen.integers(0, 2**31 - 1)
The multiple comparison procedures all allow for examining aspects of superior predictive ability. There are three available:
SPA- The test of Superior Predictive Ability, also known as the Reality Check (and accessible asRealityCheck) or the bootstrap data snooper, examines whether any model in a set of models can outperform a benchmark.StepM- The stepwise multiple testing procedure uses sequential testing to determine which models are superior to a benchmark.MCS- The model confidence set which computes the set of models which with performance indistinguishable from others in the set.
All procedures take losses as inputs. That is, smaller values are preferred to larger values. This is common when evaluating forecasting models where the loss function is usually defined as a positive function of the forecast error that is increasing in the absolute error. Leading examples are Mean Square Error (MSE) and Mean Absolute Deviation (MAD).
The test of Superior Predictive Ability (SPA)¶
This procedure requires a \(t\)-element array of benchmark losses and a \(t\) by \(k\)-element array of model losses. The null hypothesis is that no model is better than the benchmark, or
where \(L_i\) is the loss from model \(i\) and \(L_{bm}\) is the loss from the benchmark model.
This procedure is normally used when there are many competing forecasting models such as in the study of technical trading rules. The example below will make use of a set of models which are all equivalently good to a benchmark model and will serve as a size study.
Study Design¶
The study will make use of a measurement error in predictors to produce a large set of correlated variables that all have equal expected MSE. The benchmark will have identical measurement error and so all models have the same expected loss, although will have different forecasts.
The first block computed the series to be forecast.
[3]:
import statsmodels.api as sm
from numpy.random import randn
t = 1000
factors = randn(t, 3)
beta = np.array([1, 0.5, 0.1])
e = randn(t)
y = factors.dot(beta)
The next block computes the benchmark factors and the model factors by contaminating the original factors with noise. The models are estimated on the first 500 observations and predictions are made for the second 500. Finally, losses are constructed from these predictions.
[4]:
# Measurement noise
bm_factors = factors + randn(t, 3)
# Fit using first half, predict second half
bm_beta = sm.OLS(y[:500], bm_factors[:500]).fit().params
# MSE loss
bm_losses = (y[500:] - bm_factors[500:].dot(bm_beta)) ** 2.0
# Number of models
k = 500
model_factors = np.zeros((k, t, 3))
model_losses = np.zeros((500, k))
for i in range(k):
# Add measurement noise
model_factors[i] = factors + randn(1000, 3)
# Compute regression parameters
model_beta = sm.OLS(y[:500], model_factors[i, :500]).fit().params
# Prediction and losses
model_losses[:, i] = (y[500:] - model_factors[i, 500:].dot(model_beta)) ** 2.0
Finally the SPA can be used. The SPA requires the losses from the benchmark and the models as inputs. Other inputs allow the bootstrap sued to be changed or for various options regarding studentization of the losses. compute does the real work, and then pvalues contains the probability that the null is true given the realizations.
In this case, one would not reject. The three p-values correspond to different re-centerings of the losses. In general, the consistent p-value should be used. It should always be the case that
See the original papers for more details.
[5]:
from arch.bootstrap import SPA
spa = SPA(bm_losses, model_losses, seed=seed)
spa.compute()
spa.pvalues
[5]:
lower 0.273
consistent 0.320
upper 0.322
dtype: float64
The same blocks can be repeated to perform a simulation study. Here I only use 100 replications since this should complete in a reasonable amount of time. Also I set reps=250 to limit the number of bootstrap replications in each application of the SPA (the default is a more reasonable 1000).
[6]:
# Save the pvalues
pvalues = []
b = 100
seeds = gen.integers(0, 2**31 - 1, b)
# Repeat 100 times
for j in range(b):
if j % 10 == 0:
print(j)
factors = randn(t, 3)
beta = np.array([1, 0.5, 0.1])
e = randn(t)
y = factors.dot(beta)
# Measurement noise
bm_factors = factors + randn(t, 3)
# Fit using first half, predict second half
bm_beta = sm.OLS(y[:500], bm_factors[:500]).fit().params
# MSE loss
bm_losses = (y[500:] - bm_factors[500:].dot(bm_beta)) ** 2.0
# Number of models
k = 500
model_factors = np.zeros((k, t, 3))
model_losses = np.zeros((500, k))
for i in range(k):
model_factors[i] = factors + randn(1000, 3)
model_beta = sm.OLS(y[:500], model_factors[i, :500]).fit().params
# MSE loss
model_losses[:, i] = (y[500:] - model_factors[i, 500:].dot(model_beta)) ** 2.0
# Lower the bootstrap replications to 250
spa = SPA(bm_losses, model_losses, reps=250, seed=seeds[j])
spa.compute()
pvalues.append(spa.pvalues)
0
10
20
30
40
50
60
70
80
90
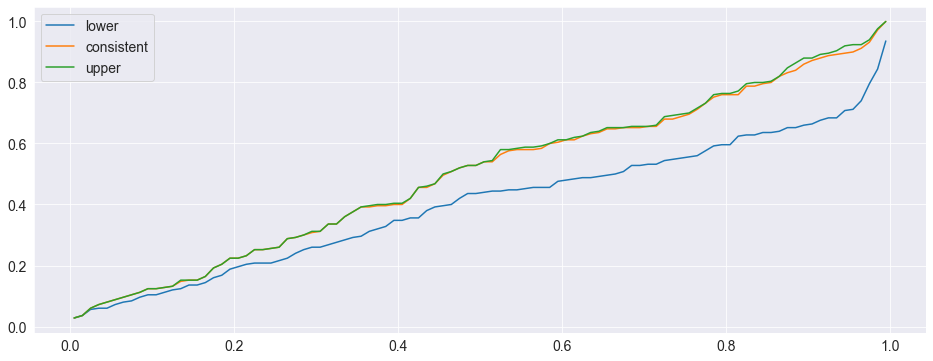
Finally the pvalues can be plotted. Ideally they should form a \(45^o\) line indicating the size is correct. Both the consistent and upper perform well. The lower has too many small p-values.
[7]:
import pandas as pd
pvalues_df = pd.DataFrame(pvalues)
for col in pvalues_df:
values = pvalues_df[col].to_numpy(copy=True)
values.sort()
pvalues_df[col] = values
# Change the index so that the x-values are between 0 and 1
pvalues_df.index = pd.Index(np.linspace(0.005, 0.995, 100))
fig = pvalues_df.plot()
Power¶
The SPA also has power to reject then the null is violated. The simulation will be modified so that the amount of measurement error differs across models, and so that some models are actually better than the benchmark. The p-values should be small indicating rejection of the null.
[8]:
# Number of models
k = 500
model_factors = np.zeros((k, t, 3))
model_losses = np.zeros((500, k))
for i in range(k):
scale = (2500.0 - i) / 2500.0
model_factors[i] = factors + scale * randn(1000, 3)
model_beta = sm.OLS(y[:500], model_factors[i, :500]).fit().params
# MSE loss
model_losses[:, i] = (y[500:] - model_factors[i, 500:].dot(model_beta)) ** 2.0
spa = SPA(bm_losses, model_losses, seed=seed)
spa.compute()
spa.pvalues
[8]:
lower 0.003
consistent 0.003
upper 0.003
dtype: float64
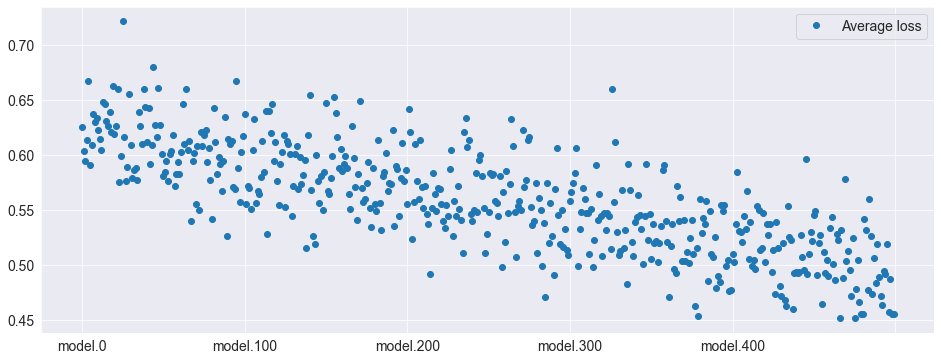
Here the average losses are plotted. The higher index models are clearly better than the lower index models – and the benchmark model (which is identical to model.0).
[9]:
model_losses_df = pd.DataFrame(
model_losses, columns=["model." + str(i) for i in range(k)]
)
avg_model_losses = pd.DataFrame(model_losses_df.mean(axis=0), columns=["Average loss"])
fig = avg_model_losses.plot(style=["o"])
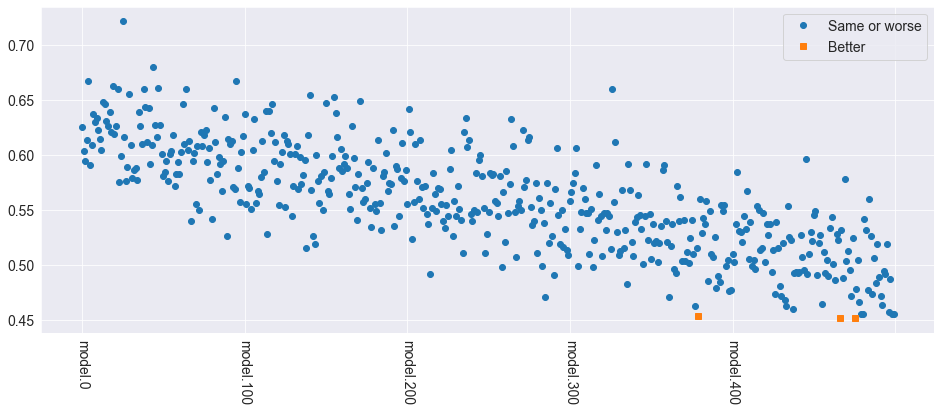
Stepwise Multiple Testing (StepM)¶
Stepwise Multiple Testing is similar to the SPA and has the same null. The primary difference is that it identifies the set of models which are better than the benchmark, rather than just asking the basic question if any model is better.
[10]:
from arch.bootstrap import StepM
stepm = StepM(bm_losses, model_losses_df)
stepm.compute()
print("Model indices:")
print([model.split(".")[1] for model in stepm.superior_models])
Model indices:
['248', '342', '353', '377', '390', '392', '411', '416', '428', '435', '436', '441', '444', '453', '456', '458', '461', '462', '471', '477', '480', '481', '486', '493']
[11]:
better_models = pd.concat(
[model_losses_df.mean(axis=0), model_losses_df.mean(axis=0)], axis=1
)
better_models.columns = pd.Index(["Same or worse", "Better"])
better = better_models.index.isin(stepm.superior_models)
worse = np.logical_not(better)
better_models.loc[better, "Same or worse"] = np.nan
better_models.loc[worse, "Better"] = np.nan
fig = better_models.plot(style=["o", "s"], rot=270)
The Model Confidence Set¶
The model confidence set takes a set of losses as its input and finds the set which are not statistically different from each other while controlling the familywise error rate. The primary output is a set of p-values, where models with a pvalue above the size are in the MCS. Small p-values indicate that the model is easily rejected from the set that includes the best.
[12]:
from arch.bootstrap import MCS
# Limit the size of the set
losses = model_losses_df.iloc[:, ::20]
mcs = MCS(losses, size=0.10)
mcs.compute()
print("MCS P-values")
print(mcs.pvalues)
print("Included")
included = mcs.included
print([model.split(".")[1] for model in included])
print("Excluded")
excluded = mcs.excluded
print([model.split(".")[1] for model in excluded])
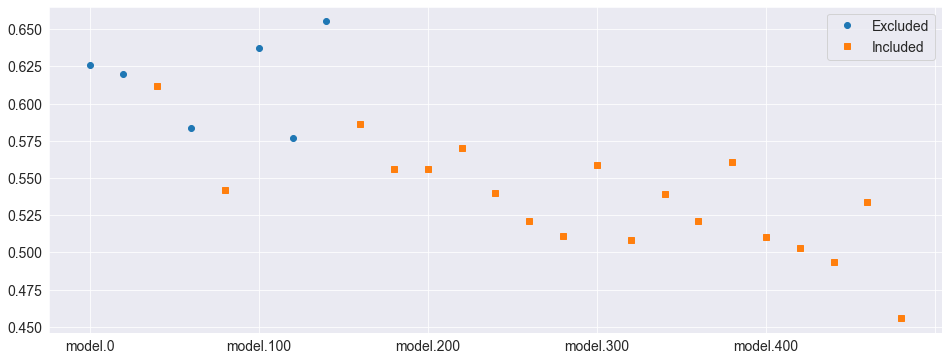
MCS P-values
Pvalue
Model name
model.0 0.000
model.200 0.000
model.40 0.000
model.280 0.001
model.20 0.001
model.100 0.003
model.220 0.003
model.160 0.006
model.140 0.026
model.300 0.032
model.240 0.058
model.120 0.116
model.360 0.116
model.180 0.116
model.60 0.133
model.80 0.272
model.320 0.451
model.440 0.561
model.380 0.561
model.260 0.561
model.340 0.561
model.420 0.561
model.460 0.561
model.400 0.561
model.480 1.000
Included
['120', '180', '260', '320', '340', '360', '380', '400', '420', '440', '460', '480', '60', '80']
Excluded
['0', '100', '140', '160', '20', '200', '220', '240', '280', '300', '40']
[13]:
status = pd.DataFrame(
[losses.mean(axis=0), losses.mean(axis=0)], index=["Excluded", "Included"]
).T
status.loc[status.index.isin(included), "Excluded"] = np.nan
status.loc[status.index.isin(excluded), "Included"] = np.nan
fig = status.plot(style=["o", "s"])